Experimentation with Variational Dropout -Do Subnetworks exist inside a Neural Network?
Variational Dropout was introduced by Yarin Gal as a mean to estimate uncertainties in prediction by neural networks. While this blog…


Variational Dropout was introduced by Yarin Gal as a mean to estimate uncertainties in prediction by neural networks. While this blog isn’t about variational dropout(Follow Yarin Gal’s Blog post for that), it is about the results that I saw while playing around with Variational dropout.
If you are aware of how Variational Dropout works, it requires the dropout to be on during the testing phase also. There are two ways to do this in keras.
def PermaDropout(rate): return Lambda(lambda x: K.dropout(x, level=rate))or
Dropout(0.5)(x, training=True)Using this, I quickly trained a 3-layer CNN network on MNIST.
inp = Input(shape=input_shape)x = Conv2D(filters=20, kernel_size=5, strides=1)(inp)x = PermaDropout(0.5)(x)x = MaxPool2D(pool_size=2, strides=2)(x)x = Conv2D(filters=50, kernel_size=5, strides=1)(x)x = PermaDropout(0.5)(x)x = MaxPool2D(pool_size=2, strides=2)(x)x = Flatten()(x)x = Dense(500, activation=’relu’)(x)x = Dropout(0.5)(x, training=True)x = Dense(num_classes, activation=’softmax’)(x)model = Model(inp, x)In 5 epochs I reached an accuracy of 98.5%. But here is the interesting part. What should be the expected behavior at test time since I am randomly dropping 50% of the weights at test time?
Results : Test loss: 0.040498659613306516Test accuracy: 0.9869Fascinating! Let’s see how the results actually change for a specific image.
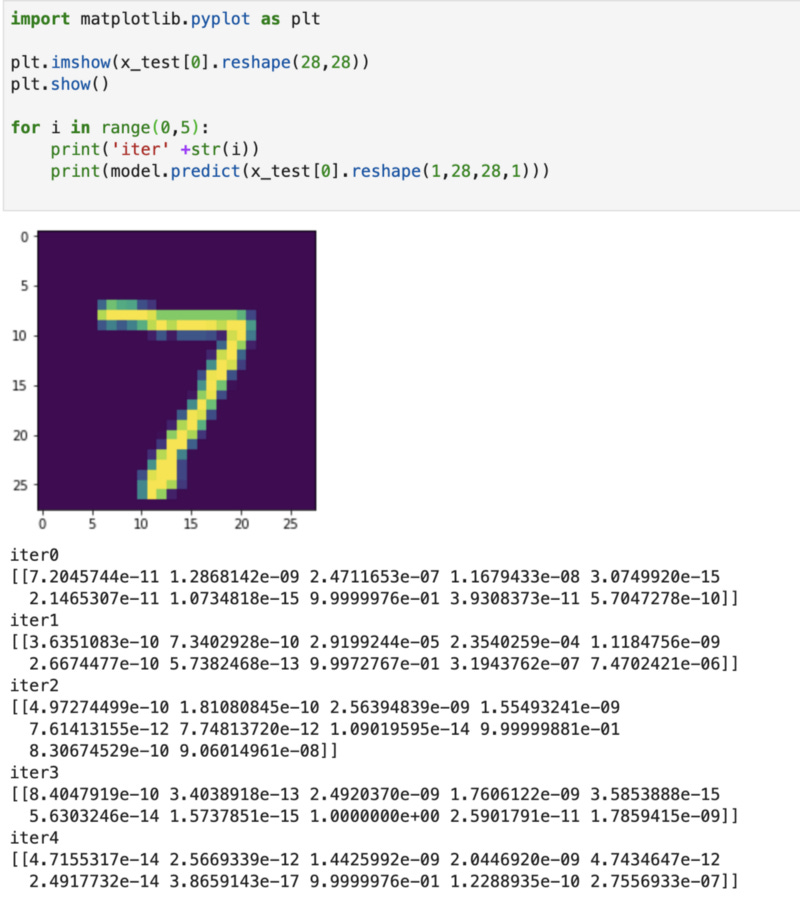
As you can see, the probabilities for classes other than 7, changed a lot, but the result came out to always correct, even though during every iteration 50% of the weights got dropped out.
Let’s do some more experiments to see what happens. Now, the dropout for the last layer is set to 0.9. I chose this experiment since the deeper layers learn complex features as opposed to the initial layers which learn basic features like edges and lines. Dropping a lot of weights in the deeper layers at test time should surely affect the results.

Nope! Still the same results.
Hmm. May be the number of neurons in the dense layer are too many. Let’s reduce them to 128 and keep the dropout 0.9.
And Yes! The network started failing.

Keep in mind this happened after we dropped 115 of 128 neurons randomly from the last layer. But even after doing this, the overall test results look like this -

This leads me to the questions -Do Subnetworks equally as good exist inside a neural network. Are the current neural network too big and can be trimmed down? Or is it just that the dataset is too simple for this experiment?
While the experiments were only conducted on MNIST, and nothing can be concluded from this, it might be directed into building more efficient neural networks by finding only the weights/layers that matter.