

You can’t always A/B test, that is why you need to learn about Quasi Experiments
Quasi Experiments for Causal Inference

Experimentations are the bread and butter of most great product companies (albeit google takes it up a notch-where you could call it insanity). Experiments need to be designed with rigor so that there is confidence that the changes are right for the customers and the business as well. While Randomized controlled experiments are the gold standard for establishing causality, but sometimes running such an experiment is not possible. Such situations can arise:
When the causal impact to be tested is not in companies control.
When establishing a Control may incur too large an opportunity cost since they do not receive the Treatment. For example, A/B experiments can be costly for rare events, such as establishing the impact of running ads during the IPL.
There is legal or ethical issues-holding information from a user about the side effects of medicine being currently tested.
When proper randomization is tough to perform.
It is not technically feasible to perform an A/B test.
For example, at MPL, we currently want to test the impact of changing our Matchmaking algorithm. All users get added to a queue and get matched on certain criteria. Doing an A/B test by randomly assigning users to test and control in this case would lead to a drop in concurrency, which in turn will increase the matchmaking time, which will affect the user experience.
In the above situations, often the best approach is to estimate the effects using multiple methods that are lower in the hierarchy of evidence -

What is a Quasi Experiment?
A quasi-experiment is an experiment where your treatment and control group are divided by a natural process that isn’t truly random but is considered close enough to compute estimates. We will use different methods to compute how close control and test are (with a lot of assumptions!).
Pitfalls
Before we dive into different methods, we must understand the pitfalls these experiments suffer from. The main pitfall, regardless of method, is unanticipated confounds that can impact both the measured effect, as well as the attribution of causality to the change of interest. Because of these confounds, quasi-experiments require a great deal of care to yield trustworthy results.
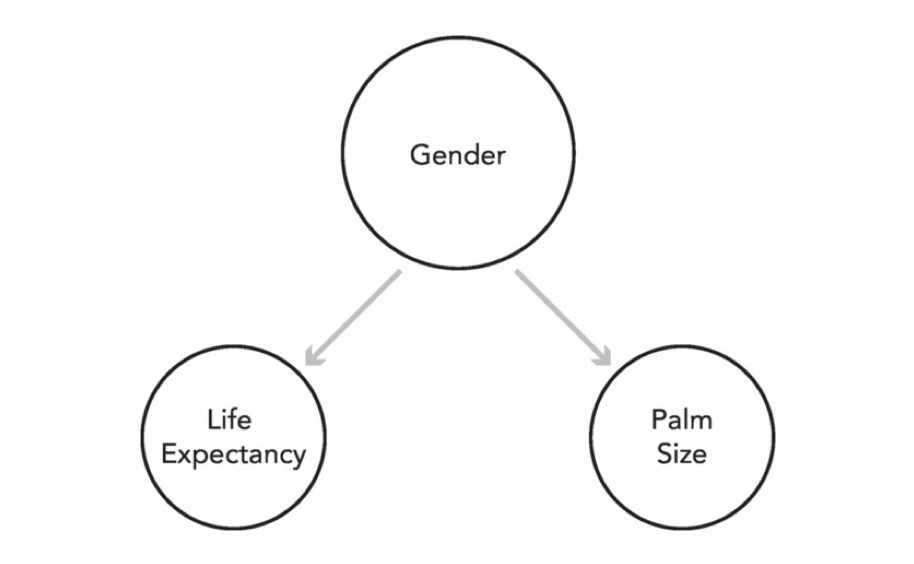
Key approaches in Quasi Experiment method
Interrupted Time Series
Interrupted Time Series (ITS) is a quasi-experimental design, where you can control the change within your system, but you cannot randomize the Treatment to have a proper Control and Treatment. Instead, you use the same population for Control and Treatment, and you vary what the population experiences over time. A good read on how Netflix uses ITS.
One of the easiest ways to conduct ITS is to do an on and off experiments-run the intervention for a particular period, then switch off and run without the intervention.

2. Bayesian Structural Time Series
(one of the best articles explaining BSTs- Tfcausalimpact)
I will shamelessly use what the author of the above post has used because it is quite literally one of the easiest explanations I have read -
The main goal of the algorithm is to infer the expected effect a given intervention (or any action) had on some response variable by analyzing differences between expected and observed time series data.
Data is divided in two parts: the first one is what is known as the “pre-intervention” period and the concept of Bayesian Structural Time Series is used to fit a model that best explains what has been observed. The fitted model is used in the second part of data (“post-intervention” period) to forecast what the response would look like had the intervention not taken place. The inferences are based on the differences between observed response to the predicted one which yields the absolute and relative expected effect the intervention caused on data.
At MPL we extensively use this library.We used it to prove the positive effect of our new matchmaking algorithm -



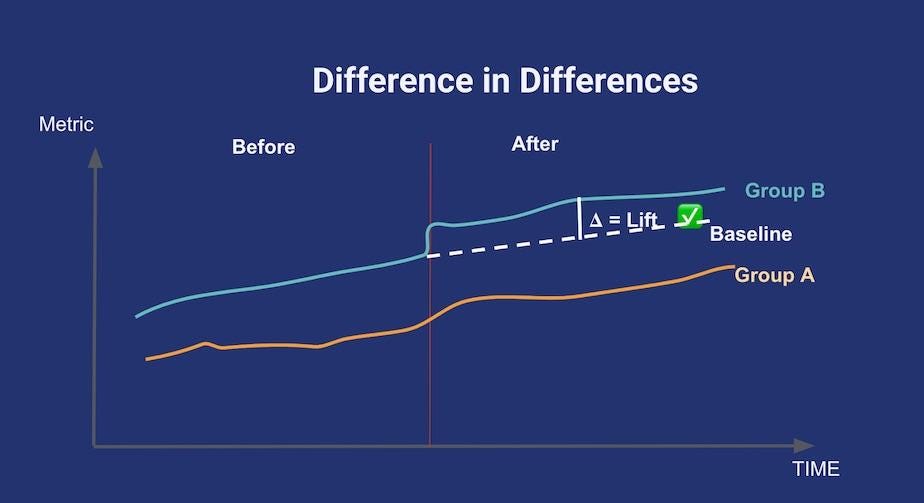
3. Difference in Difference
For this method to be applicable, you have to find a control group that shows a trend that’s parallel to your treatment group for the metric of interest, prior to any treatment being applied. Then, after treatment happens, you assume the break in the parallel trend is only due to the treatment itself. This is summed up in the above diagram. At MPL, we use a mix of correlation and cointegration between different games PDAU(playing Daily active users), CPDAU, total gameplays, and retention (and of course do a sanity check with the operations team) to find these similar groups.

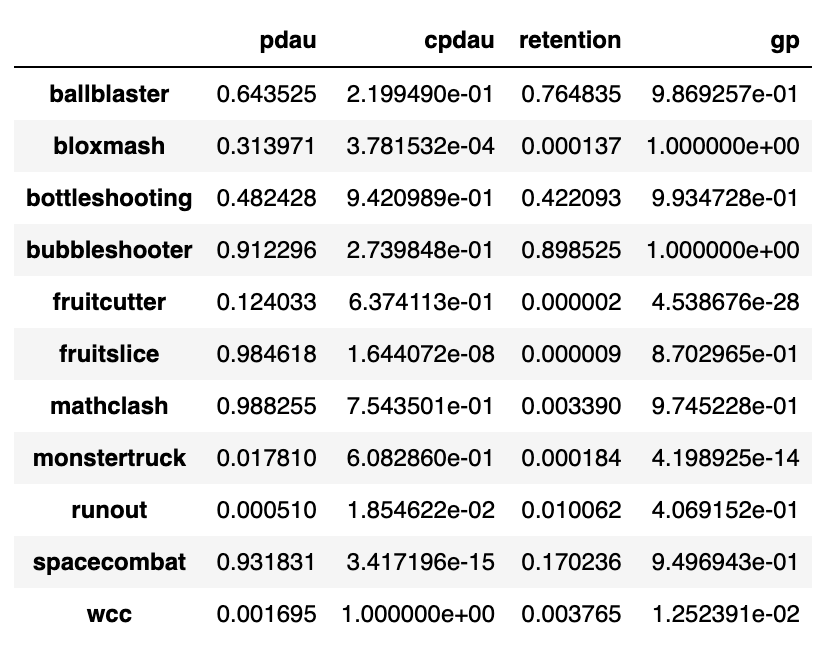
This method worked for us, as for fruitchop we got fruitcutter as one of the games, both of them belong to the same category as well are very similar games with very similar user distribution.
Conclusion
While A/B tests are still the gold standard for proving causation, not being able to perform randomized tests shouldn’t block us from experimenting. Quasi experimentation is a powerful tool for causal inference when used right!