

There is still opportunity for Indic Large Models
No language left behind

I have been spending quite some time reading papers on multilingual and multimodal language-vision model. But this paper seems like an inflection point on my following thesis -

There is still opportunity in Indic Models
Don’t get me wrong — building a foundational, generic model is by no means an easy task. There is a reason why no open-source model is even close to gpt-3.5, let alone gpt-4 (which is an engineering feat in itself). And most people will disagree, with extremely good counter points (TAM probably is too small). I am wrong till proven right.
But there are following indicators that it can be done using current open-source models as base, and get to gpt3.5 kind of performance on indic language benchmarks. From there we can start thinking about Mixture of experts to reach the mighty GPT-4 in performance on Indic benchmarks.
GPT-4 is still behind on indic languages as compared to the top languages.
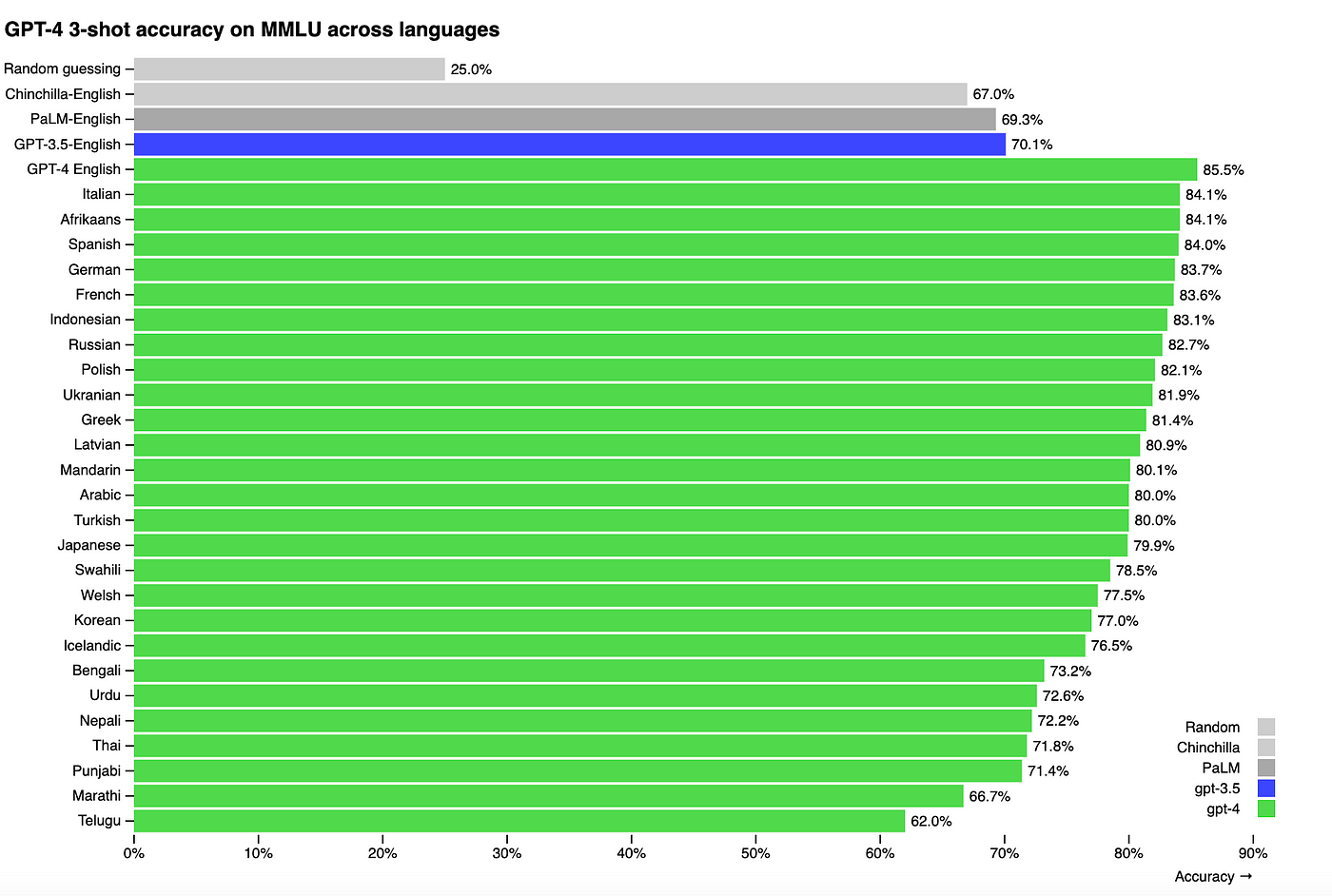
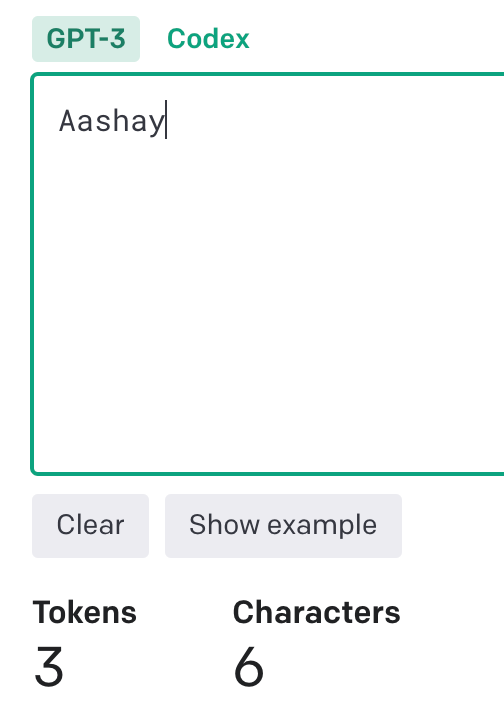
2. At India’s “DAU Farm” scale, openai’s api would be extremely expensive. Indian Language tokens already consume 2–3x more tokens, and if every products needs to have intelligence embedded, we need better alternatives.

3. LLMs are evolving into platforms — LLMs are amazing parsers. We have seen this with Agent frameworks (ability to call functions), Chatgpt Plugin platform. Mark in the podcast with lex talks about how AI agents will be present in every Meta app, built on top of Llama. Scale, Palantir have shown a demo of LLMs in defence — they act as command centers. For something evolving into something so critical, why would we not want to build something of our own? And India’s biggest strength has been building country level platforms (UPI, Aadhar etc). May be we can show the way how to build platforms around LLM.
4. We can build much smaller models and they can be coherent in language, this isn’t likely a property just related to large models. Recent work has shown targeted distillation on specific tasks can create smaller and much better models.
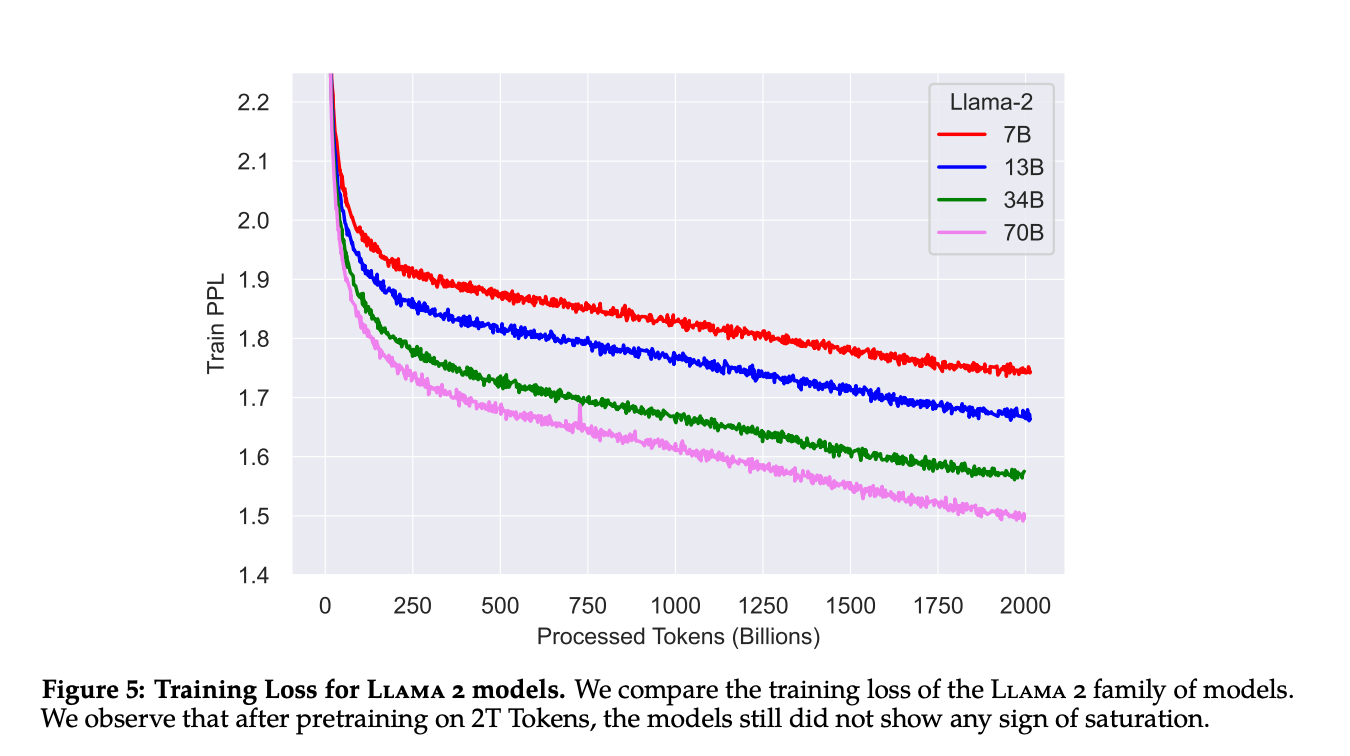
5. llama has shown small models can become good enough — the loss for 7B doesn’t saturates. Smaller models will have much lesser inference cost and can be easily finetuned to fit specific usecases from the base model. Scale is not the only metric to optimise for(check out the image from PALM paper). One of openai’s biggest achievement has been able to serve reliably gpt3.5.

We haven’t even moved in multi-modality. Most of India prefers audio as means of conversation, a platform like chatgpt only serves a very small population.

Vision models carry inherent biases.

I had created a sample model finetuned via LoRA, but it already feels three generations old. The current roadmap would be — finetune a code based LLM which supports multilingual (salesforce xgen is a good example) + use AI4Bharat indic corpora + instruction fine tuning combining open source datasets + evol instruct technique (added caveat being we will need to translate which will bump up the error).
aashay96/indic-BloomLM · Hugging Face
If you are building in this space, happy to have a chat. Connect with me on Twitter or linkedin.